
Pemanfaatan Large Language Model (LLM) dalam pengembangan perangkat lunak semakin umum digunakan untuk mempercepat proses penulisan kode. Namun, kecepatan tidak selalu berbanding lurus dengan kualitas. Kode yang dihasilkan AI tetap berpotensi mengandung bug, security issue, atau technical debt jika tidak melalui evaluasi yang tepat.
Melalui pendekatan code quality analysist menggunakan SonarQube, artikel ini mengeksplorasi bagaimana karakteristik kode dari beberapa LLM terkenal dapat dianalisis secara objektif. Tujuannya bukan untuk membandingkan mana yang “paling pintar”, melainkan memahami bagaimana SonarQube membantu menjaga kualitas kode di era pengembangan berbasis AI.
Latar Belakang
Penggunaan Large Language Models (LLM) seperti GPT-4o, Claude, dan Llama kini telah menjadi bagian yang tak terpisahkan dari Software Development Life Cycle (SDLC). AI kini mempercepat penulisan kode, membantu memecahkan masalah dalam programing, serta meningkatkan produktivitas developer secara signifikan.
Namun menurut laporan “The Code Personalities of Leading LLMs” (Sonar, Oktober 2025) menunjukan fakta penting yang sering diabaikan.
LLM memang mampu menulis working code, tetapi secara konsisten gagal dalam menulis kode yang secure, compliance, dan maintainable.
Disinilah perlu lapisan kontrol yang wajib dalam pengembangan Software Modern.
Pendekatan
Berbeda dengan evaluasi AI biasanya yang hanya mengandalkan Benchmark fungsional, dalam laporan tersebut Sonar menggunakan pendetakan yang jauh lebih dalam.
Disini Sonar melakukan analisis pada kode yang dihasilkan oleh setiap model AI dengan menggunakan SonarQube enterprise static analysis engine, yang telah dikembangkan selama lebih dari 16 tahun untuk mendeteksi:
- Bug
- Vulnerabilities
- Security Hotpots
- Code Smells
- Technical Debt
Analisis dilakukan pada model AI dengan mengerjakan 4.442 Java programming assignments dari sumber terkenal, termasuk MultiPL-E-mbpp-java, MultiPL-E-humaneval-java, dan ComplexCodeEval.
| MultiPL-E benchmarks | GPT-5-minimal | Claude Sonnet 4 | Claude 3.7 Sonnet | GPT-4o | Llama 3.2 90B | OpenCoder-8B |
| HumanEval (158 tasks) | 91.77% | 95.57% | 84.28% | 73.42% | 61.64% | 64.36% |
| MBPP (385 tasks) | 68.13% | 69.43% | 67.62% | 68.13% | 61.40% | 58.81% |
| Weighted test Pass@1 avg | 75.37% | 77.04% | 72.46% | 69.67% | 61.47% | 60.43% |
Tabel 1: Performa LLM pada MultiPL-E Java benchmarks (source: The Coding Personalities of Leading LLMs).
Metrik Penilaian yang Digunakan
Sonar tidak menilai “apakah kode dapat berjalan”, tetapi apakah kode layak dijalankan, dengan menggunakan beberapa metrik yaitu:
- Bug Density
- Vulnerabilities (BLOCKER, CRITICAL, MAJOR)
- Code Smell Density
- Cycle & Cognitive Complexity
- Comment Density
- Code Volume (LOC)
| LLM Model | BLOCKER % | CRITICAL % | MAJOR % | MINOR % |
| GPT-5-minimal | 35.00 | 31.67 | 3.33 | 30.00 |
| Claude Sonnet 4 | 59.57 | 28.37 | 5.67 | 6.38 |
| Claude 3.7 Sonnet | 56.03 | 28.45 | 5.17 | 10.34 |
| GPT-4o | 62.50 | 23.21 | 5.36 | 8.93 |
| Llama 3.2 90B | 70.73 | 22.76 | 1.63 | 4.88 |
| OpenCoder-8B | 64.18 | 26.87 | 1.49 | 7.46 |
Tabel 2: Distribusi tingkat kerentanan (source: The Coding Personalities of Leading LLMs).
| LLM | % Bugs | % Vulnerabilities | % Code smells |
| GPT-5-minimal | 4.67% | 0.46% | 94.87% |
| Claude-Sonnet-4 | 5.85% | 1.95% | 92.19% |
| Claude-3.7-Sonnet | 5.35% | 1.76% | 92.88% |
| GPT-4o | 7.41% | 2.05% | 90.54% |
| Llama 3.2 90B | 7.71% | 2.38% | 89.90% |
| OpenCoder-8B | 6.33% | 1.72% | 91.95% |
Tabel 3: Distribusi dari tipe issue yang dihasilkan oleh LLM (source: The Coding Personalities of Leading LLMs).
Laporan ini menunjukkan bahwa semua model LLM yang di tes, memiliki kelemahan dan kelebihan yang sama, yaitu:
Kelebihan:
- Mampu menghasilkan kode yang valid secara syntax
- Cukup mampu dalam memecahkan masalah algoritma
- Sangat efektif untuk mempercepat masa awal development
Kelemahan:
- Lemah dalam regulasi software development
- Meninggalkan banyak celah keamanan
- Sering gagal menutup resource (file, stream, connection)
- Menghasilkan hardcodded secrets
- Sering menghasilkan messy code
Setiap LLM Mempunyai “Kepribadian” yang Unik
Sama seperti developer pada umumnya, Sonar menemukan bahwa setiap model AI memiliki kepribadian yang berbeda, disebut juga sebagai coding personality. Kepribadian ini diukur berdasarkan sifat-sifat seperti:
- Kevokalan: Seberapa banyak kode yang ditulis
- Kompleksitas: Seberapa rumit struktur dan logika kode
- Komunikasi: Seberapa banyak komentar yang menjelaskan isi kode
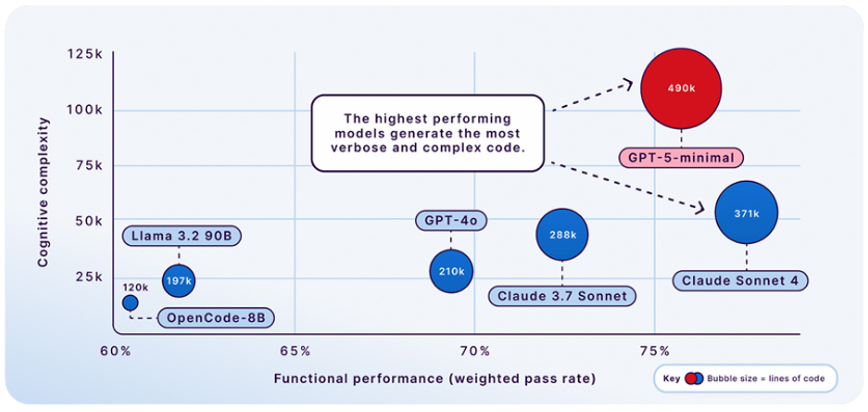
| LLM Model | Lines of Code (LOC) | Comments (%) | Cyclomatic Complexity | Cognitive Complexity |
| GPT-5-minimal | 490,010 | 2.10% | 145,099 | 111,133 |
| Claude-Sonnet-4 | 370,816 | 5.10% | 81,667 | 47,649 |
| Claude-3.7-Sonnet | 288,126 | 16.40% | 55,485 | 42,220 |
| GPT-4o | 209,994 | 4.40% | 44,387 | 26,450 |
| Llama 3.2 90B | 196,927 | 7.30% | 37,948 | 20,811 |
| OpenCoder-8B | 120,288 | 9.90% | 18,850 | 13,965 |
Tabel 4: Komparasi metrik dari kode yang dihasilkan masing-masing LLM (source: The Coding Personalities of Leading LLMs).
Tipe “Kepribadian” Model AI
Berdasarkan laporan “The Code Personalities of Leading LLMs”, Sonar mengelompokkan model LLM menjadi beberapa archetypes:
| LLM | Coding archetype |
Functional skill (pass rate %) |
Issue density (Issues/KLOC) |
Verbosity (LOC) |
Cognitive complexity |
Dominant flaw type (% of total issues) |
| GPT-5minimal | The baseline performer |
75.37% | 26.65 | 490,010 | 111,133 | 94.87% code smells |
| Claude Sonnet 4 | The senior architect |
77.04% | 19.48 | 370,816 | 47,649 | 92.2% code smells |
| Claude 3.7 Sonnet | The balanced predecessor |
72.46% | 22.82 | 288,126 | 42,220 | 92.9% code smells |
| GPT-4o | The efficient generalist |
69.67% | 26.08 | 209,994 | 26,450 | 90.5% code smells |
| Llama 3.2 90B | The unfulfilled promise |
61.47% | 26.20 | 196,927 | 20,811 | 89.9% code smells |
| OpenCoder-8B | The rapid prototyper |
60.43% | 32.45 | 120,288 | 13,965 | 92.0% code smells |
Tabel 4: LLM archetypes (source: The Coding Personalities of Leading LLMs).
1. Developer Senior – Claude Sonnet 4
- Kode yang dibuat memiliki kevokalan dan kompleksitas yang tinggi
- Banyak lapisan proteksi
- Risiko tinggi di bug concurrency dan resource leak
Perlu diperhatikan:
Kode yang dihasilkan terlihat “enterprise-ready“, tetapi justru menyembunyikan critical bug yang sulit dideteksi.
2. Model Awal yang Seimbang – Claude Sonnet 3.7
- Dokumentasi terbaik (16,7% komentar)
- Kode mudah dibaca oleh developer
- Menghasilkan sejumlah besar kerentanan tingkat BLOCKER
Perlu diperhatikan:
Kode yang terlihat rapi dan terdokumentasi dengan baik, tidak otomatis menjadi kode yang aman.
3. Model Umum yang Efisien – GPT-4o
- Kompleksitas sedang
- Cocok untuk penggunaan umum
- Sangat sering membuat kesalahan alur logika (48% bug)
Perlu diperhatikan:
Terdapat bug “halus” yang mungkin lolos di testing awal namun dapat muncul di lingkungan Production.
4. Ekspektasi yang Tidak Terpenuhi – Llama 3.2 90B
- Dengan Skala dan didukung oleh perusahaan besar, namun hasilnya biasa
- 70% kerentanan yang dihasilkan tergolong BLOCKER
- Hasil keamanan paling buruk dari semua model yang di uji coba
Perlu diperhatikan:
Walaupun dari segi skalanya yang besar dan mendapat dukungan dari perusahaan besar, penggunaan model ini untuk Production sangat berisiko.
5. Rapid Prototyper – OpenCoder-8B
- Kode yang paling sedikit (LOC rendah)
- Cocok untuk tahap awal Development atau PoC
- Banyak menghasilkan technical debt
Perlu diperhatikan:
Menghasilkan 42% code smell yang berasal dari dead & unused code.
6. Model Penalaran – GPT-5 (minimal mode)
- Akurasi fungsional terbaik
- Kompleksitas ekstrem
- Keamanan tertinggi
Perlu diperhatikan:
Walaupun kode yang dihasilkan memiliki keamanan tertinggi, namun tingkat kompleksitasnya yang tinggi juga membuat kode lebih sulit untuk di-maintain oleh developer. Jika dibandingkan dengan model lainnya yang menghasilkan kerentanan yang umum dan sederhana, model yang lebih canggih justru menghasilkan kerentanan yang kompleks dan sulit dideteksi oleh manusia.
| Metric | Claude 3.7 Sonnet (Older) | Claude Sonnet 4 (Newer) | GPT-5-minimal |
| Benchmark pass rate | 72.46% | 77.04% | 75.37% |
| % of Vulnerabilities that are ‘BLOCKER’ | 56.03% | 59.57% | 35.00% |
| % of Bugs from ‘Concurrency/Threading’ | 1.44% | 9.81% | 20.00% |
Tabel 5: LLM archetypes (source: The Coding Personalities of Leading LLMs).
Mengapa SonarQube Menjadi Solusi di Era AI?
“AI mempercepat penulisan kode, tetapi membuat risiko dari bug sederhana ke bug kompleks yang sulit dideteksi manusia.” Di sinilah SonarQube hadir untuk:
- Menyediakan verifikasi objektif
- Menjaga standar konsistensi
- Mengontrol risiko keamanan (Vulnerabilities)
- Menekan Technical Debt sejak awal
Pendekatan yang tepat bukan “percaya pada AI”, melainkan:
“Trust, but verify”
Di masa depan, sebagian besar kode akan ditulis dengan bantuan AI. Namun artikel ini menegaskan satu hal penting:
“Tanpa SonarQube, AI bukan sumber inovasi melainkan sumber dari risiko tersembunyi”
Kenapa demikian? Karena SonarQube memastikan bahwa:
- Kecepatan tidak mengorbankan Security
- Inovasi tidak menciptakan Technical Debt
- Kode AI tetap layak digunakan di Production
Hasil analisis ini memperlihatkan bahwa meskipun LLM mampu mempercepat proses development, kualitas kode tetap memerlukan kontrol yang konsisten. Tanpa pengukuran yang jelas, risiko maintainability dan keamanan dapat meningkat seiring bertambahnya penggunaan AI dalam penulisan kode.
Pendekatan berbasis SonarQube memberikan visibilitas yang dibutuhkan untuk menilai kualitas kode secara objektif, baik yang ditulis oleh developer maupun dihasilkan oleh AI.
Mari diskusikan dengan tim i3 mengenai praktik code quality dan penerapannya di lingkungan pengembangan modern dapat menjadi langkah awal untuk memastikan standar kualitas tetap terjaga seiring evolusi teknologi.
Written by: Masagus Rayhan Bayhaqi, Consultant DevOps
Edited by: Pipit Pirda Damayanti, Marketing